Manjari GanapathyinGeek CultureWhat happens when you update Common Table Expressions (CTEs)?Advance your SQL skills in CTEsJul 3, 20211Jul 3, 20211
Manjari GanapathyinNerd For TechFinding Outliers in SQLUsing Median absolute deviation to find the outliers using SQL ServerJul 2, 20211Jul 2, 20211
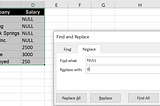
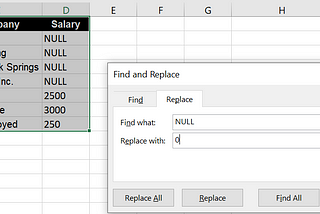
Manjari GanapathyinGeek CultureData Cleaning in MS Excel and SQLA comparison between MS Excel and SQL and MS Excel for data cleaningMay 25, 2021May 25, 2021
Manjari GanapathyinTowards Data ScienceAn Investigation Into Federated LearningA decentralized machine learning technique without sharing raw dataJan 13, 2021Jan 13, 2021